31 Backend Developer Interview Questions That Work

On this page
- What a Good Backend Technical Interview Looks Like
- API Fundamentals — REST, GraphQL, and Auth
- How do you design a RESTful API? What makes an API RESTful?
- What is the difference between REST and GraphQL?
- Explain the difference between authentication and authorization
- Database Interview Questions — Joins, Indexing, Transactions, and the N+1 Trap
- What are the main types of SQL joins?
- When should you add an index — and when should you avoid one?
- Walk me through ACID and isolation levels
- What is the N+1 query problem?
- Caching and Rate Limiting Interview Questions
- What are common caching strategies?
- How does Redis work, and what are its common use cases?
- How would you implement rate limiting in an API?
- Messaging and Event-Driven Architecture
- When would you use a message queue instead of a direct API call?
- How does Apache Kafka differ from traditional message queues?
- Concurrency and System Design
- What is a deadlock? How do you prevent one?
- Horizontal vs vertical scaling — when do you reach for each?
- Reliability and Observability
- What is observability? How is it different from monitoring?
- How to Structure a Backend Technical Screen
- 30-Minute Screen Format
- 60-Minute Technical Interview
- Scoring Backend Interview Answers
- Explore All 31 Backend Developer Interview Questions
Most backend developer interview questions test trivia, not engineering judgment. Reciting the difference between PUT and PATCH tells you nothing about whether a candidate can design an API that survives a traffic spike or debug a deadlock at 2 a.m. Good questions create a gradient — accessible enough for mid-level engineers, deep enough for seniors to expose real production scars. This guide highlights 14 of the strongest backend developer interview questions from our seed bank of 31, with scoring guidance.
TL;DR: 14 highlighted backend developer interview questions across APIs, databases, caching, messaging, concurrency, and observability — with reference answers, scoring rubrics, and ready-to-use 30-/60-minute screen formats. The complete set of 31 is available on our backend developer interview questions page.
What a Good Backend Technical Interview Looks Like
A backend technical interview should map to the surface area of the role: HTTP-level API design, the database, the cache, the queue, and the runtime that has to keep everything coordinated under load. Trivia leaves chunks of that surface area untested.
Our seed bank ships 31 calibrated questions across 8 categories — Programming Fundamentals, Databases, API Design, DevOps, Security, Caching, Messaging, and Monitoring — and 3 difficulty tiers (easy, medium, hard). Each question carries a markdown prompt and a markdown reference answer that the interviewer sees at runtime, so screens stay consistent across the team.
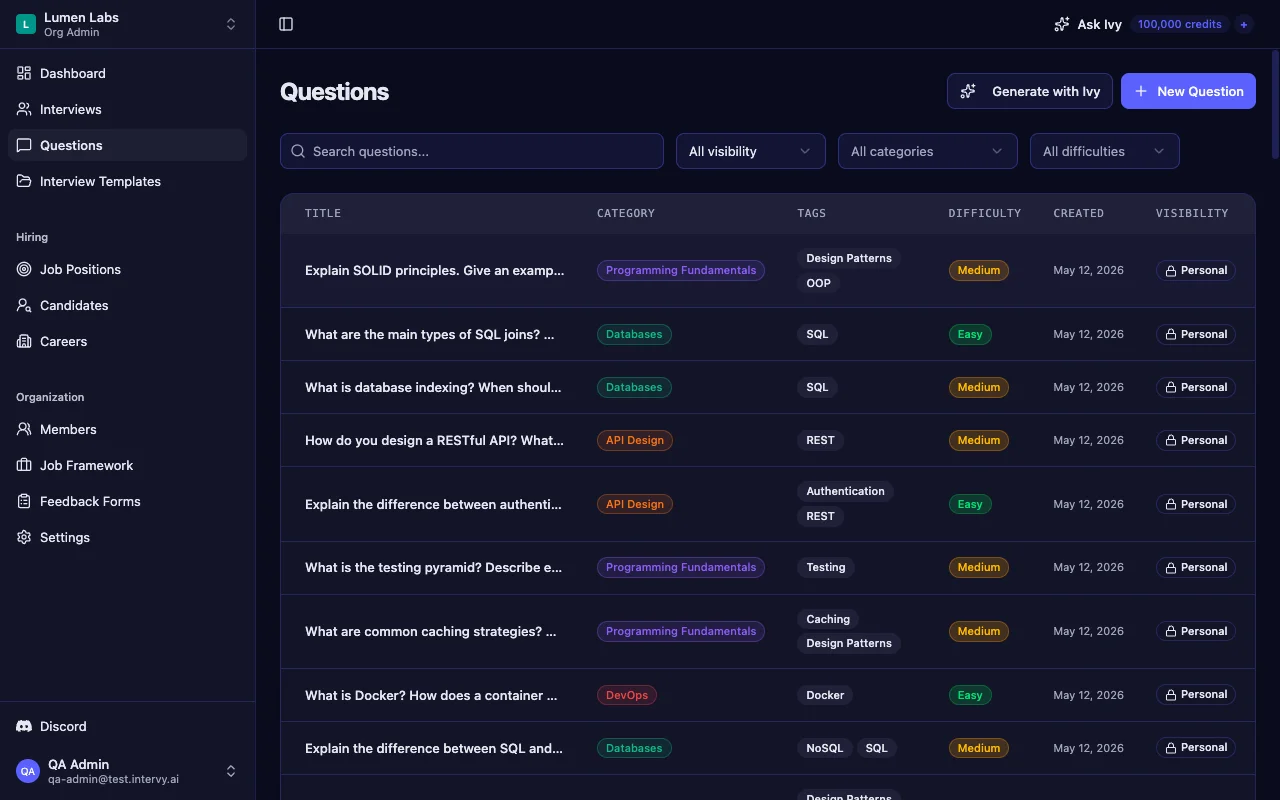
Tip: Pick questions that span at least 4 of the 8 categories in a single screen. A backend candidate who breezes through API design but folds at the first database isolation question is not yet a senior backend engineer — you only learn that by going wide.
API Fundamentals — REST, GraphQL, and Auth
API design is the most visible part of the backend role. Gaps in resource modeling, status codes, or auth flows leak into every endpoint a candidate ships.
How do you design a RESTful API? What makes an API RESTful?
Look for resource-oriented URLs (/users/123/orders, not /getOrdersForUser?id=123), correct verb-to-status-code mapping (200/201/204/400/401/403/404/500), pagination, and versioning. Strong candidates contrast PUT (full replacement, idempotent) with PATCH (partial update) and explain when HATEOAS is worth the cost.
| Action | Verb | Success status | Notes |
|---|---|---|---|
| Create | POST | 201 Created | Return new resource or Location |
| Read | GET | 200 OK | Safe + idempotent, cache-friendly |
| Replace | PUT | 200 / 204 | Idempotent, full representation |
| Patch | PATCH | 200 / 204 | Partial update, not idempotent |
| Delete | DELETE | 204 | Idempotent — second call still returns |
What is the difference between REST and GraphQL?
Baseline answers cover single endpoint vs many and client-controlled response shape. Strong answers surface the fixed disadvantages of GraphQL — caching is harder, resolvers introduce N+1 problems, query-cost attacks are real — and mention persisted queries plus DataLoader as the standard mitigations.
query CandidateWithApplications($id: ID!) { candidate(id: $id) { name applications { jobPosition { title } status } } }
Explain the difference between authentication and authorization
AuthN is "who you are." AuthZ is "what you can do." Bonus credit for walking through a JWT structure (header.payload.signature), explaining why short access-token expiries plus refresh tokens are the modern default, and contrasting httpOnly cookies with localStorage.
Key takeaway: API questions reveal whether a candidate has actually shipped HTTP services. Anyone can recite verbs — you want the engineer who can defend a status code choice under pressure.
Database Interview Questions — Joins, Indexing, Transactions, and the N+1 Trap
Databases are where backend candidates either prove or disprove their senior instincts. These four database interview questions span the range from "can you JOIN" to "can you reason about isolation."
What are the main types of SQL joins?
INNER, LEFT, RIGHT, FULL OUTER, and CROSS. The trap question is hidden in the predicate: NULL never equals NULL, so a join on a nullable column silently drops rows. Senior candidates mention IS NOT DISTINCT FROM (Postgres) or COALESCE as the fix.
SELECT u.email, o.id AS order_id FROM users u LEFT JOIN orders o ON o.user_id = u.id WHERE o.created_at >= NOW() - INTERVAL '7 days';
When should you add an index — and when should you avoid one?
Index high-cardinality columns, foreign keys, and columns used in WHERE, JOIN, and ORDER BY. The trade-off: every write maintains the index. Strong candidates know B-tree vs hash and explain the leftmost-prefix rule — a composite index on (org_id, created_at) does not help a query that filters only on created_at.
Walk me through ACID and isolation levels
Atomicity, Consistency, Isolation, Durability — with a concrete example for each. Then push into isolation levels:
| Level | Dirty reads | Non-repeatable reads | Phantom reads |
|---|---|---|---|
| Read Uncommitted | Allowed | Allowed | Allowed |
| Read Committed | Prevented | Allowed | Allowed |
| Repeatable Read | Prevented | Prevented | Allowed |
| Serializable | Prevented | Prevented | Prevented |
Senior candidates name the default in Postgres (Read Committed), in MySQL/InnoDB (Repeatable Read), and explain why "stronger is always better" is wrong — Serializable kills throughput under contention.
What is the N+1 query problem?
Query count grows linearly with the size of the parent list. Fixes range from a JOIN to ORM eager loading (include, joinedload) to DataLoader batching in GraphQL. Senior candidates mention ORM query logging and tools like Bullet.
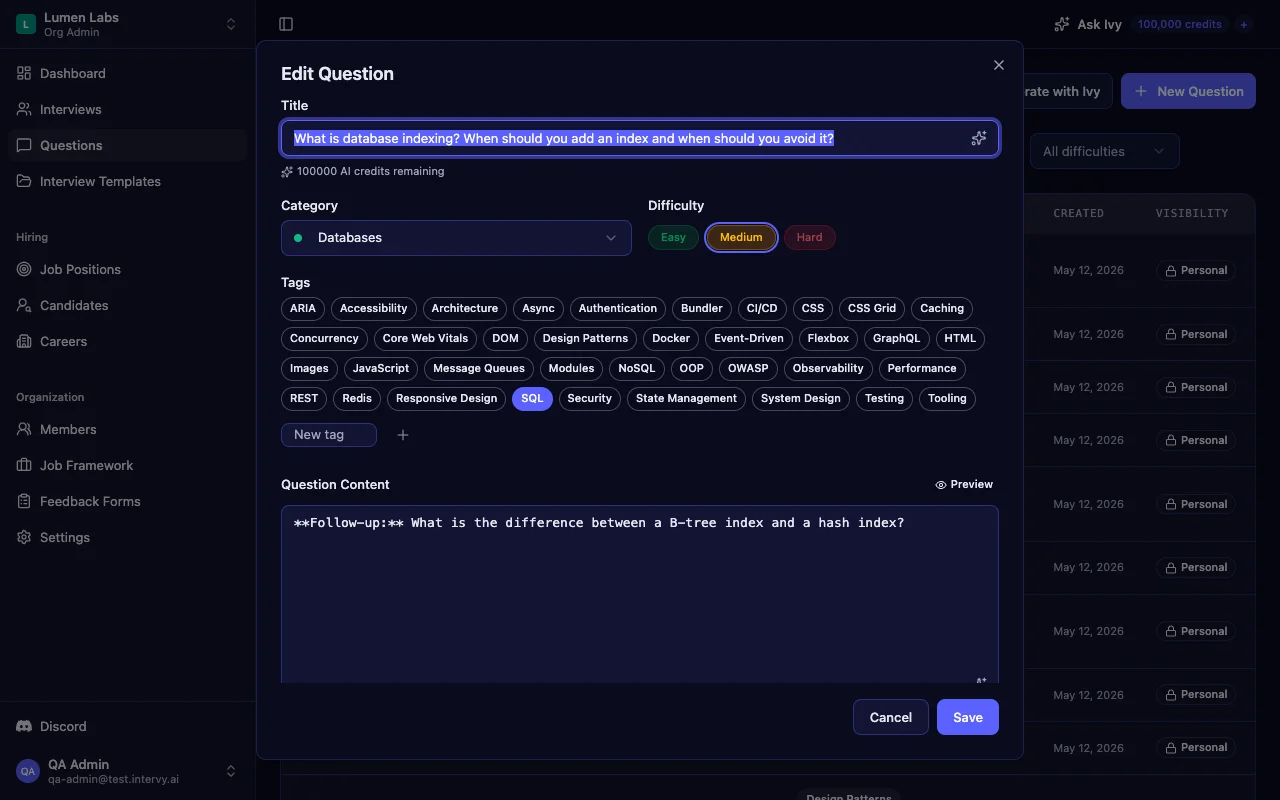
Tip: Ask the indexing question, then immediately follow with: "We added an index — query is still slow. What do you check next?" Strong answers cover query plans (
EXPLAIN ANALYZE), statistics staleness, and predicate sargability.
Caching and Rate Limiting Interview Questions
Caching is where backend engineers prove they understand state — or get exposed by it. Phil Karlton's line — "there are only two hard things in computer science: cache invalidation and naming things" — is the entire category in one sentence.
What are common caching strategies?
Cache-aside, write-through, write-behind, and refresh-ahead. Strong answers walk through invalidation (TTL, event-driven, versioned keys) and acknowledge the right strategy depends on read/write ratio and staleness tolerance.
- Cache-aside. App checks cache, falls back to DB on miss, writes to cache. Most common, simplest to reason about.
- Write-through. Every write hits cache and DB synchronously. Strong consistency, slower writes.
- Write-behind. Writes go to cache, persisted to DB asynchronously. Fast writes, durability risk.
How does Redis work, and what are its common use cases?
Sub-millisecond latency. Single-threaded command processing. Core data structures: strings, hashes, lists, sets, sorted sets, streams. Use cases: session store, sliding-window rate limiting, leaderboards, pub/sub. Bonus credit for RDB vs AOF persistence and the durability trade-off.
How would you implement rate limiting in an API?
Fixed window vs sliding window vs token bucket. The X-RateLimit-* and Retry-After headers, returning 429. Senior candidates flag the burst problem at fixed-window boundaries — a client can fire 2× the limit in 1 second by straddling the edge.
async function isAllowed(userId: string, limit = 100, windowSec = 60) { const key = `rate:${userId}:${Math.floor(Date.now() / 1000 / windowSec)}`; const count = await redis.incr(key); if (count === 1) await redis.expire(key, windowSec); return count <= limit; }
Key takeaway: Caching questions test mental models of state. A candidate who reaches for Redis the moment they hear "slow query" without asking "is the cache invalidation cost worth it?" is still mid-level.
Messaging and Event-Driven Architecture
Once a backend system grows past one box, async messaging stops being optional. These questions test delivery-guarantee reasoning — the most under-appreciated topic in backend interviews.
When would you use a message queue instead of a direct API call?
Decoupling, traffic absorption, fan-out, and long-running tasks. Strong candidates explain the three delivery semantics — at-most-once, at-least-once, exactly-once — and insist consumers be idempotent, because exactly-once delivery is exactly-once effect plus at-least-once delivery.
How does Apache Kafka differ from traditional message queues?
Pull vs push. Retained log vs delete-on-ack. Partitions with per-partition ordering. Consumer groups for horizontal scaling. Offset replay for reprocessing. Bonus for naming when Kafka is overkill (use SQS/RabbitMQ) and when only Kafka works (event sourcing, multi-consumer fan-out, audit log as system-of-record).
Tip: After Kafka, ask: "How do you make a consumer idempotent?" If the answer is hand-wavy, drill into the actual mechanics — dedupe table keyed on message ID, idempotency keys in the upstream API, or content-addressed processing. This is where engineers who have operated a queue diverge from engineers who have only consumed one.
Concurrency and System Design
The bridge from "I write backend code" to "I run backend systems" is concurrency. These system design interview questions reveal whether a candidate can reason about contention, not just code around it.
What is a deadlock? How do you prevent one?
Two transactions, each holding a lock the other needs. The DB picks a victim and rolls it back. Prevention: consistent lock ordering, short transactions, and SELECT ... FOR UPDATE SKIP LOCKED for job-queue patterns where workers should grab the next available row instead of blocking.
BEGIN; SELECT id FROM jobs WHERE status = 'pending' ORDER BY created_at FOR UPDATE SKIP LOCKED LIMIT 1; -- ... process job, then UPDATE/COMMIT
Horizontal vs vertical scaling — when do you reach for each?
Vertical first — it is cheap and avoids distributed-systems failure modes. Horizontal once you hit a hard ceiling on a single box, need geographic distribution, or care about failure isolation. Senior candidates name the costs: stateless services, shared session stores, distributed tracing, and consensus protocols when state has to be shared.
Key takeaway: Concurrency questions reveal the gap between developers and engineers. Anyone can write a loop — only operators have stared at a deadlock graph at 3 a.m.
Reliability and Observability
Observability is the difference between "we know something is wrong" and "we know exactly why" — one of the most predictive senior signals on the screen.
What is observability? How is it different from monitoring?
Monitoring answers questions you already knew to ask. Observability lets you answer new ones. The three pillars: metrics (Prometheus, Datadog), logs (structured JSON + correlation IDs), and traces (Jaeger, Tempo). Bonus for naming OpenTelemetry as the vendor-neutral SDK that unifies them.
- Metrics. Aggregated time-series — what is the p99 latency right now?
- Logs. Discrete events with context — what exactly happened on this request?
- Traces. A request's path across services — where did the 800 ms go?
The signal you want from a senior candidate: "I would not ship a service without a request_id on every log line."
How to Structure a Backend Technical Screen
Knowing the right questions is half the battle. A structured format ensures consistent evaluation across candidates.
30-Minute Screen Format
- Minutes 0-2: Introduction — role overview, set expectations
- Minutes 2-10: API + auth rapid-fire — REST design, auth vs authz, one status-code scenario
- Minutes 10-22: Database deep-dive — indexing trade-offs or the N+1 problem
- Minutes 22-28: Async + queue scenario — when to introduce a queue, idempotency follow-up
- Minutes 28-30: Candidate questions
60-Minute Technical Interview
- Minutes 0-5: Warmup — auth vs authz, joins
- Minutes 5-25: Database + caching — indexing, ACID/isolation, cache invalidation
- Minutes 25-45: System design — rate-limited API with Redis and a queue; partitioning, idempotency, observability follow-ups
- Minutes 45-55: Senior reach — deadlocks, Kafka vs queue, three pillars of observability
- Minutes 55-60: Interviewer notes — score immediately while context is fresh
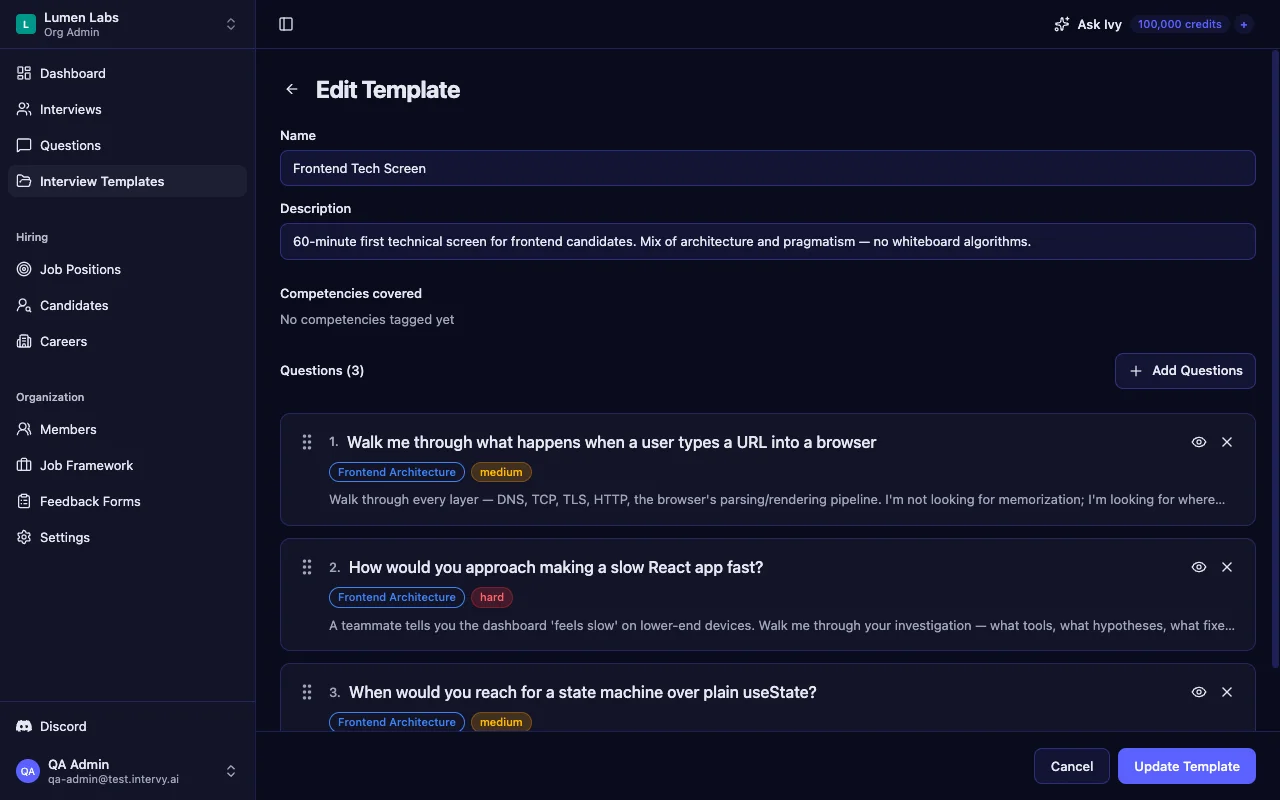
Building reusable templates with an interview template builder ensures every interviewer asks calibrated questions at the right difficulty level. The backend seed ships with a starter "Backend Developer Interview" template that references 10 of the 31 questions in order — import it and edit rather than building from scratch.
Scoring Backend Interview Answers
Consistent scoring turns interviews from gut feelings into hiring signal. Intervy uses a 5-point scale as part of the interview scoring tool workflow.
- Strong No (1) — cannot answer or gives fundamentally incorrect information
- No (2) — partial understanding with significant gaps
- Maybe (3) — factually correct but surface-level
- Yes (4) — solid answer with trade-offs and real-world context
- Strong Yes (5) — exceptional depth, surfaces edge cases unprompted, offers alternatives
| Question | Maybe (3) | Yes (4) | Strong Yes (5) |
|---|---|---|---|
| RESTful API design | Names resources + verbs | Adds status codes + pagination | Contrasts PUT/PATCH, defends HATEOAS choice |
| ACID + isolation | Defines the four properties | Walks the isolation-level matrix | Names DB defaults, explains throughput cost |
| N+1 problem | Recognizes the symptom | Names the fix (JOIN / eager load) | Mentions DataLoader, query logging, profiling |
| Rate limiting | Picks one algorithm | Adds headers + 429 | Explains fixed-window burst at boundaries |
| Kafka vs queue | Pull vs push | Partitions + consumer groups | Defends when not to use Kafka |
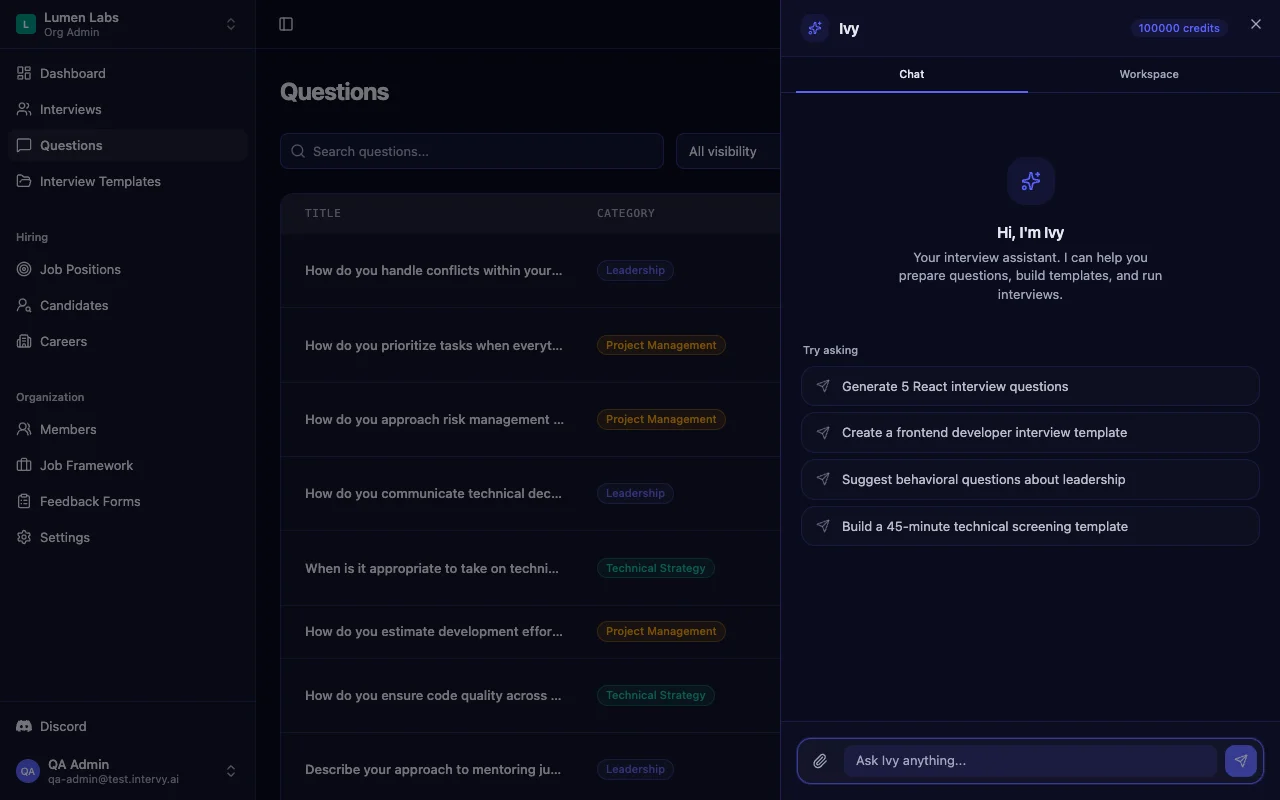
Ivy, Intervy's AI copilot, can draft new backend questions in the same shape the seed uses — markdown prompt, reference answer, difficulty, category, and tags — making it straightforward to extend the seed for your stack, whether that is Go on Kubernetes or a Python monolith on Postgres. Ivy can also read an uploaded CV and propose targeted follow-ups tied to the candidate's experience — the biggest time-saver for senior backend screens.
Key takeaway: A rubric does not eliminate disagreement — it makes disagreement productive. Two interviewers can score the same answer a 3 and a 4, then have a useful conversation about why instead of arguing in the abstract.
Explore All 31 Backend Developer Interview Questions
This guide highlighted 14 of the most revealing backend developer interview questions. The complete set of 31 — with full reference answers, code examples, difficulty ratings, and category tags — lives on our backend developer interview questions page.
For a broader view, see our complete guide to technical interview questions. Backend candidates often overlap with Python work, so our Python interview questions guide pairs naturally; for Node.js backends, see our JavaScript interview questions guide.
Want to use these in your next interview? Grab all 31 at once — head to our Import section and load the "Backend Developer Interview" sample set into your Intervy workspace. The import drops in both the question bank entries and a starter template, so your team is one click from a calibrated screen.