How to Score Candidates Fairly: A Rubric-Driven Guide

On this page
- Why Unstructured Scoring Leaks Bias
- The Anatomy of a Fair Candidate Scoring Rubric
- Competencies Carry the Definition
- Anchoring Ratings: What 3/5 Actually Means
- Why 5-Level Beats 10-Level Most of the Time
- Snapshotting: Why Retroactive Edits Can't Rewrite History
- Aggregating Panel Scores Without Averaging Away Signal
- Mapping Questions to Competencies
- Calibration: Closing the Gap Between Interviewers
- The Calibrated Debrief: Beyond Per-Question Scores
- Putting It Together
Three salespeople interview the same candidate for an Account Executive role. One scores her a clear "yes." Another marks her "maybe." The third says "no — didn't love the energy." Same candidate, same 45 minutes, three completely different verdicts. The problem isn't your panel. You're asking three people to score against three different rubrics in their heads. A real candidate scoring rubric closes that gap.
TL;DR: A fair candidate scoring rubric defines what each rating level means in writing, breaks the score down by competency, and snapshots itself at interview start so retroactive edits can't rewrite history. Get those three layers right and panel debates shift from "vibes" to evidence.
Why Unstructured Scoring Leaks Bias
When interviewers score from gut feel, noise drowns signal. The halo effect makes a polished opener pull every later rating upward. Recency bias makes the final answer count three times. Anchoring locks the whole panel onto whatever the first interviewer thought. These aren't character flaws — they're how human judgment works without a structured interview tool to constrain it.
The leak gets worse across functions because each one has its own vague vocabulary for the same problem. In sales it's "culture fit." In product it's "executive presence." In customer success it's "empathy." In engineering it's "I'd grab a beer with them." All four phrases mean the same thing: the interviewer formed an unscored impression and is now searching for a label that justifies it.
Tip: If you can't write down what a "3" means before the interview starts, your panel will invent a definition during the interview — and each panelist will invent a different one.
The fix isn't to suppress judgment. It's to make judgment legible. A candidate scoring rubric forces every interviewer to commit to the same definitions of "good," "great," and "no" before they meet the candidate.
The Anatomy of a Fair Candidate Scoring Rubric
A rubric isn't a vibe-check spreadsheet. It's a small set of explicit decisions you make once, then apply consistently. Three layers do most of the work:
- Per-question criteria. Every question gets its own rating, not just one overall score. A candidate can ace one question and bomb the next — your rubric should show both.
- Anchored rating scale. Each level on your scale has a written definition shared across all interviewers. No private interpretations.
- Per-competency rollups. Questions map to competencies — communication, problem-solving, customer empathy, system design — so ratings aggregate into a competency-level read, not just a single average.
Intervy's data model is built around exactly these three layers. Each answer stores a numeric rating, a comment, and the question it answered. Per-answer scoring isn't a nice-to-have — without it you can't build any of the higher layers.
Competencies Carry the Definition
A rubric also needs to define what "Senior" actually means versus "Mid" or "Junior" — and that definition has to be specific to each competency, not a single paragraph at the role level. Intervy models this as a competency × level matrix per job role: rows are competencies, columns are levels, and each cell holds the guideline text for that intersection.
Key takeaway: A scoring rubric is three coordinated decisions — what you measure (competencies), how you measure it (anchored scale), and how it adds up (per-question to per-competency). Skip any one and the rubric collapses into a vibe check with extra steps.
Anchoring Ratings: What 3/5 Actually Means
The highest-leverage move in any candidate scoring rubric is writing labels for every level. "3" is meaningless. "Maybe — meets expectations but didn't impress" is a rubric. Two interviewers using the same anchored label land within one level of each other; two interviewers using bare numbers can be two levels apart and not realize it.
Intervy ships three presets:
- Simple (3-level). No / Maybe / Yes. Best for early screens where you need a hire-bar binary plus "investigate further."
- Standard (5-level). Strong No / No / Maybe / Yes / Strong Yes. The default — granular enough to express conviction, narrow enough that calibration stays cheap.
- Detailed (10-level). 1 Unacceptable to 10 Outstanding. Useful for late-stage panels where small deltas matter and interviewers are already well-calibrated.
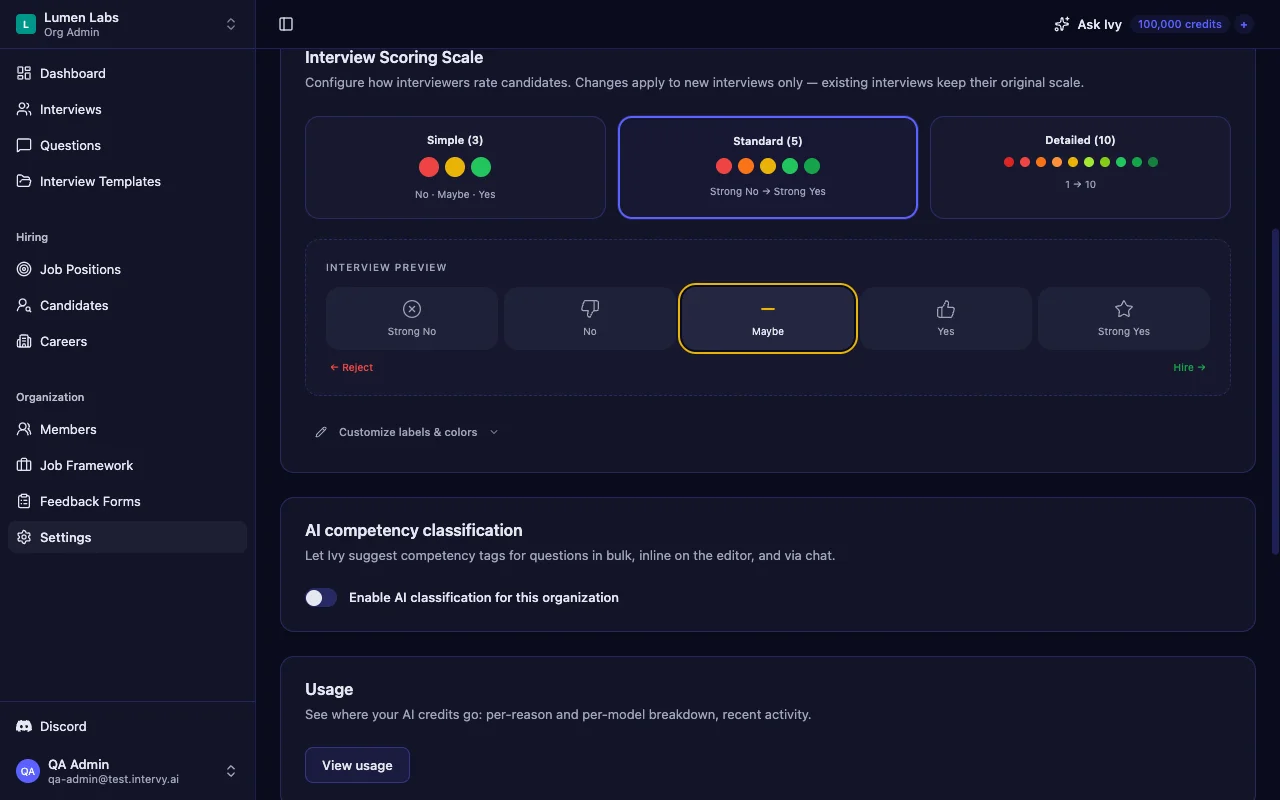
Each scale is validated: 2 to 10 levels, labels capped at 30 characters, colors as valid hex codes, values incrementing sequentially from 1.
Why 5-Level Beats 10-Level Most of the Time
10-level scales feel more "scientific" but they're harder to calibrate. The difference between "7" and "8" is the kind of thing two interviewers will disagree on forever. "Yes" versus "Strong Yes" is much easier to anchor with examples ("Strong Yes = I would actively fight to hire this person"). Start with Standard; move to Detailed only once your panel is already calibrated.
Tip: Write level labels as observable outcomes — "delivered a complete answer without prompting" beats "good." Outcomes are inter-rater agreeable. Adjectives are not.
Snapshotting: Why Retroactive Edits Can't Rewrite History
Here's a subtle but important property of a fair rubric: once you've used it to score a candidate, you can't change it. If you switch in Q3 from a 5-level to a 10-level scale, every Q1 and Q2 interview must keep its original scale — otherwise you've rewritten the past.
Intervy enforces this in the database:
- Snapshot at start. When an interview starts, the current scoring scale is snapshotted onto that interview.
- Validate against snapshot. When the review page reads back a rating, it validates against the snapshot, not the live setting.
- Forward-only change. The settings UI calls it out: "Changes apply to new interviews only — existing interviews keep their original scale."
Without snapshotting, every retroactive scale change would silently rewrite your hiring history — and any audit defense you'd want to build on it.
Key takeaway: A scoring rubric only earns the word "fair" when it's locked at the moment of evaluation. Editable history is just rewriting the past with extra steps.
Aggregating Panel Scores Without Averaging Away Signal
One overall number is the worst possible output of a panel interview. It lets the loudest interviewer dominate, hides skill gaps behind averages, and erases the per-competency story that should drive your hire decision. A real candidate scoring rubric surfaces three layers of aggregation at once — and the panel debates the breakdown, not the headline.
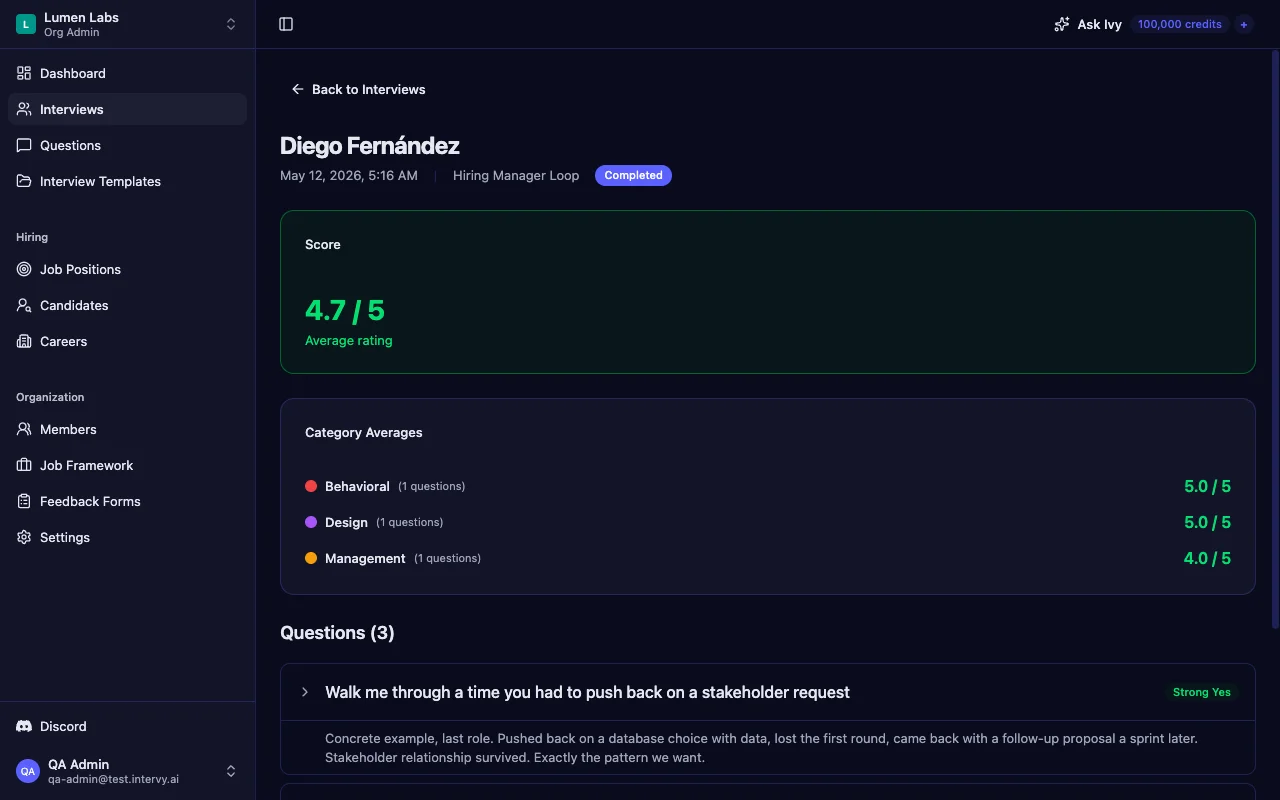
Intervy's review page renders all three:
- Overall average. A single overall score card showing e.g. 3.8 / 5 with color-coded styling from the anchored scale. Useful for triage, useless for decisions on its own.
- Per-category averages. Answers are grouped by competency, the mean computed per category, and sorted descending. This is where you see that a PM candidate scored 4.6 on prioritization but 2.5 on stakeholder communication — a profile, not a number.
- Per-question detail. Each question shows the rating with its anchored label ("Strong Yes"), the interviewer's comment, and an expandable view of the question and reference answer. The raw evidence behind every average.
Mapping Questions to Competencies
For the category layer to mean anything, your questions have to be tagged. Intervy lets each question map to one or more competencies, and that mapping drives the rollup. Ratings are then grouped by competency and phase, averaged per group, and reported with a question count so you can see how much evidence each cell rests on. A 4.5 backed by six questions is much stronger signal than a 4.5 backed by one.
Tip: If your overall score and your per-competency scores tell different stories, trust the breakdown. The overall is a summary statistic; the per-competency view is the actual data.
Calibration: Closing the Gap Between Interviewers
A rubric reduces interviewer drift but doesn't eliminate it. Two well-meaning interviewers can still apply "Strong Yes" to slightly different bars — one anchors on "exceptional," the other on "solidly above target." The fix is calibration, and most of the work happens in human conversation, not the product.
A useful pre-loop calibration session:
- Pick a mock candidate transcript. Five to ten answers — one clear "yes," one clear "no," several ambiguous ones.
- Score independently. Every panelist rates each answer using the anchored scale, with no discussion.
- Surface the deltas. Anywhere two interviewers are more than one level apart, stop and discuss.
- Sharpen the anchors. If "Strong Yes" keeps producing disagreement, the definition is too vague — rewrite it.
Key takeaway: Calibration is a team process, not a product feature. The product's job is to make the rubric and reference baseline impossible to ignore. The team's job is to keep arguing about edge cases until the anchors are sharp.
The Calibrated Debrief: Beyond Per-Question Scores
Per-question and per-competency scores tell you what happened in the interview. They don't capture an interviewer's final synthesis — "I'd hire her, but I'm concerned about her ability to push back on a difficult VP." For that you need structured feedback fields on top of the per-question rubric.
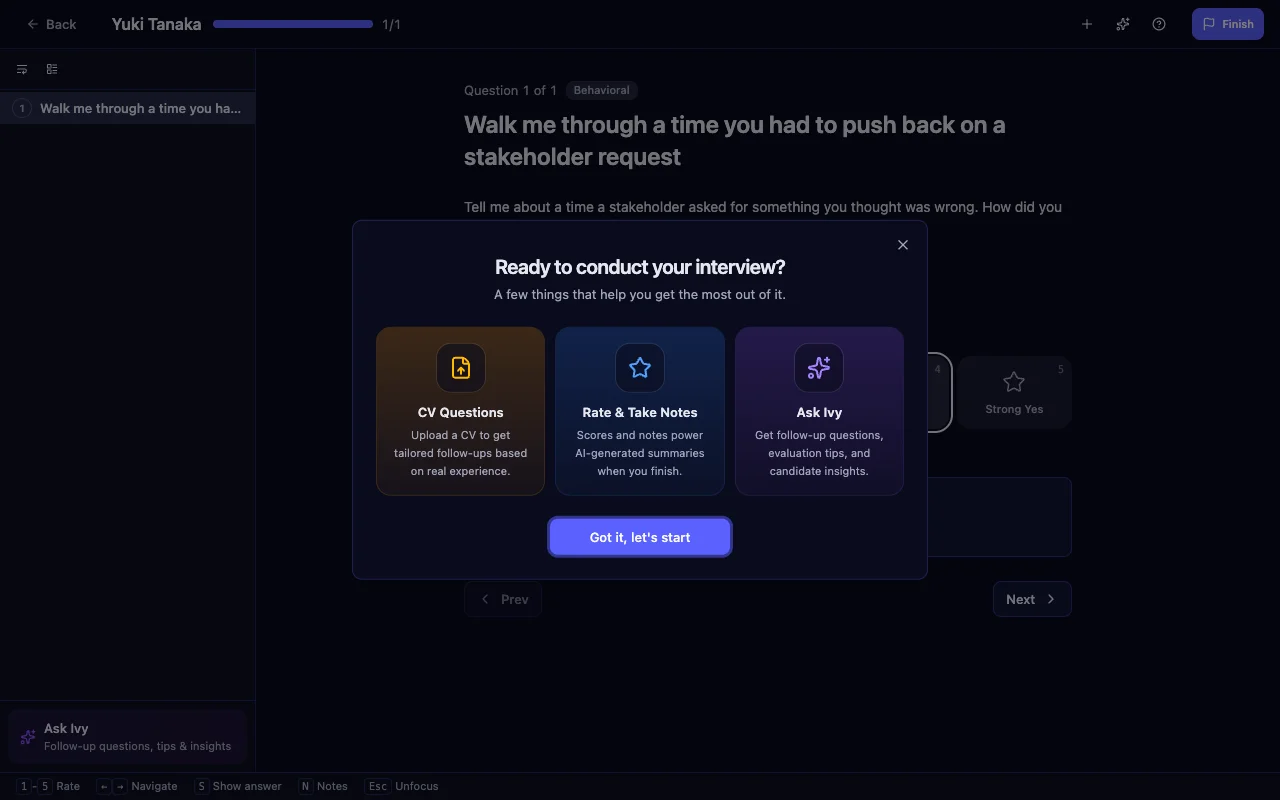
Intervy's feedback forms support four field types — rating, select, multi-select, and text — and two special roles: recommendation and concerns. A rating field renders configurable star levels with optional anchored labels, so a feedback form can include its own "hire confidence" scale separate from per-question ratings.
A useful pattern:
- Hire recommendation. A 4-point anchored field — Strong No / No / Yes / Strong Yes — set to the recommendation role.
- Top concerns. A free-text concerns field to capture what could derail the hire.
- Strengths observed. A multi-select field mapped to your competency list — fast to fill, easy to aggregate across panelists.
The form is submitted per interview and shown on the review page with the panelist's name. Three interviewers, three forms, three sets of structured recommendations — side by side in the debrief, instead of one Slack thread of vibes. Reference answers do the same job inside the interview itself: Intervy stores a Markdown reference answer per question and surfaces it inline during conduct and review so the calibration anchor travels with the interview.
If you haven't built the underlying interview structure yet, our structured technical interviews guide walks through the four-step process this rubric sits on top of.
Putting It Together
A candidate scoring rubric isn't a document you write once and file away. It's the operational shape of your hiring loop: configured presets, tagged competencies, mapped questions, and a debrief that runs on data instead of impressions. Each layer reinforces the others — the anchored scale works because questions roll up into competencies, and competencies roll up cleanly because every answer has its own rating.
Start small. Pick one role, write three to five competencies, draft a guideline per level, and run two interviews end-to-end with a 5-level anchored scale. The first debrief feels slightly mechanical. The third feels impossibly fast — your panel is arguing about actual gaps in the breakdown instead of fishing for words to describe a vibe.
Once the rubric is in place, AI can speed up the question prep that feeds it — see how to prepare for technical interviews with AI. Try it in Intervy and configure your scoring scale, competencies, and templates in Org Settings.