Reducing Bias in Interviews: 7 Practices That Work

On this page
- 1. Define the Rubric Before You Write the Questions
- 2. Ask Every Candidate the Same Core Questions
- 3. Score in the Moment, on an Anchored Scale
- 4. Anonymize What You Can
- 5. Watch for the Cultural-Fit Fallacy
- 6. Calibrate the Panel Before Each Role Goes Live
- 7. Audit Who Did What After the Funnel Runs
- Common Pitfalls
- Getting Started
Most bias in interviews isn't malice. It's drift. One interviewer asks about a Fortune 500 stakeholder pushback; the next asks about scaling a Kubernetes cluster. Different question, different bar, different hire. Reducing bias in interviews is rarely about good intentions — it's about removing the unstructured moments where personal heuristics take over. Google's well-known internal research on hiring found that structured interviews predict job performance more reliably than unstructured ones, and that finding has held up across broader meta-analytic work. The fix is procedural, not philosophical.
TL;DR: Reducing bias in interviews comes from seven structural habits — written rubrics, same core questions for every candidate, in-the-moment anchored scoring, anonymized profiles, retiring "cultural fit," panel calibration, and auditing the trail. None of them require a new department; all of them get cheaper with the right structured interview tool.
1. Define the Rubric Before You Write the Questions
The first bias vector isn't the question — it's the bar. If "Senior" means one thing to the hiring manager and something else to the second interviewer, the panel is averaging two different scales.
Start with a competency × level matrix per role. List the four to seven competencies that actually predict success — Discovery, Objection Handling, and Commercial Awareness for sales; Stakeholder Management, Prioritization, and Technical Fluency for a PM; Reliability Engineering, Code Review, and Incident Response for an SRE. Then write what each level looks like for each competency: not a label, a sentence.
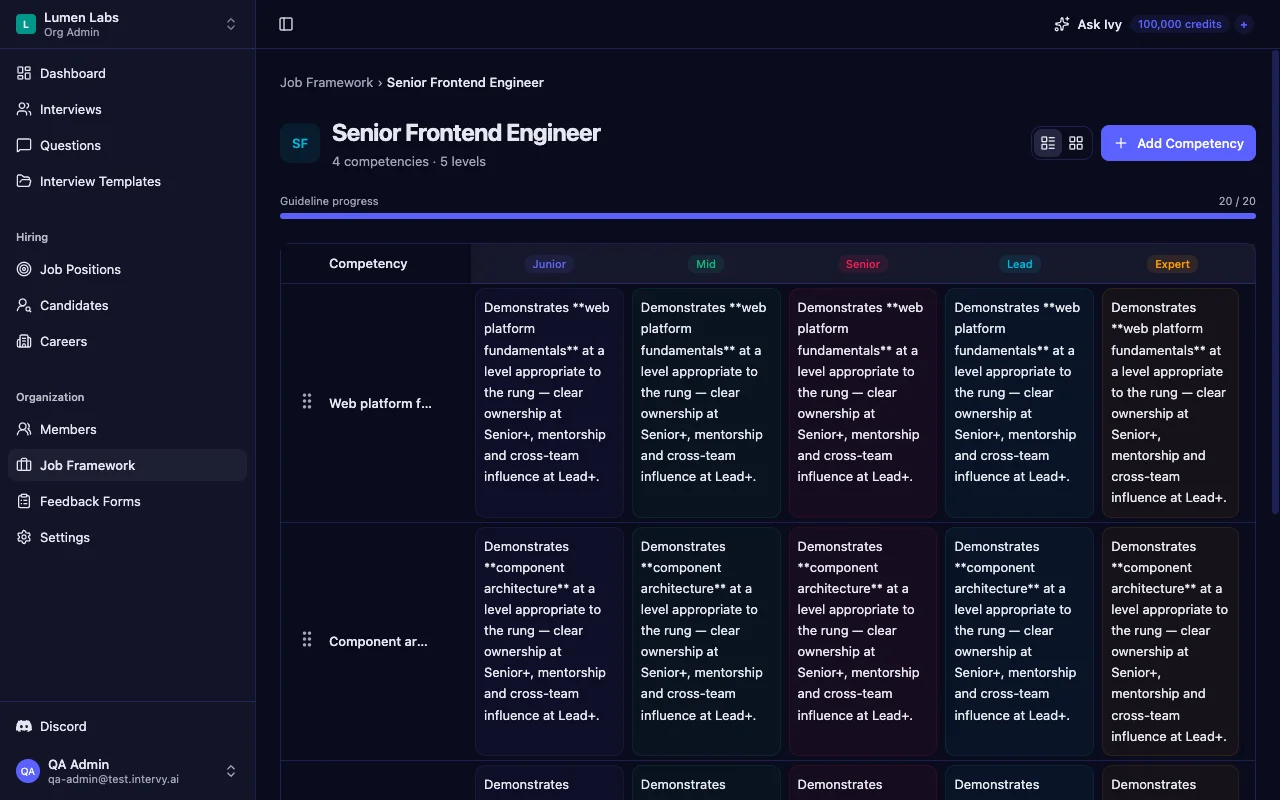
In Intervy, that matrix is data. Every competency has a row per level (Junior, Mid, Senior, Lead, Expert) with its own guideline text, and each cell is edited independently — so the rubric is iteratively refined and every interviewer reads the same current text.
Tip: If you can't write a one-sentence guideline for "Mid Discovery skills," you don't have a rubric — you have a vibe. Vibes are exactly what affinity bias rides in on. Write the sentence first, even if it's bad, and refine it on the second hire.
2. Ask Every Candidate the Same Core Questions
The most common bias pattern is question drift: the interviewer who got along with the candidate asked the easy version, the one who didn't asked the hard version, and the debrief argues about "performance" as if both panels ran the same test. They didn't.
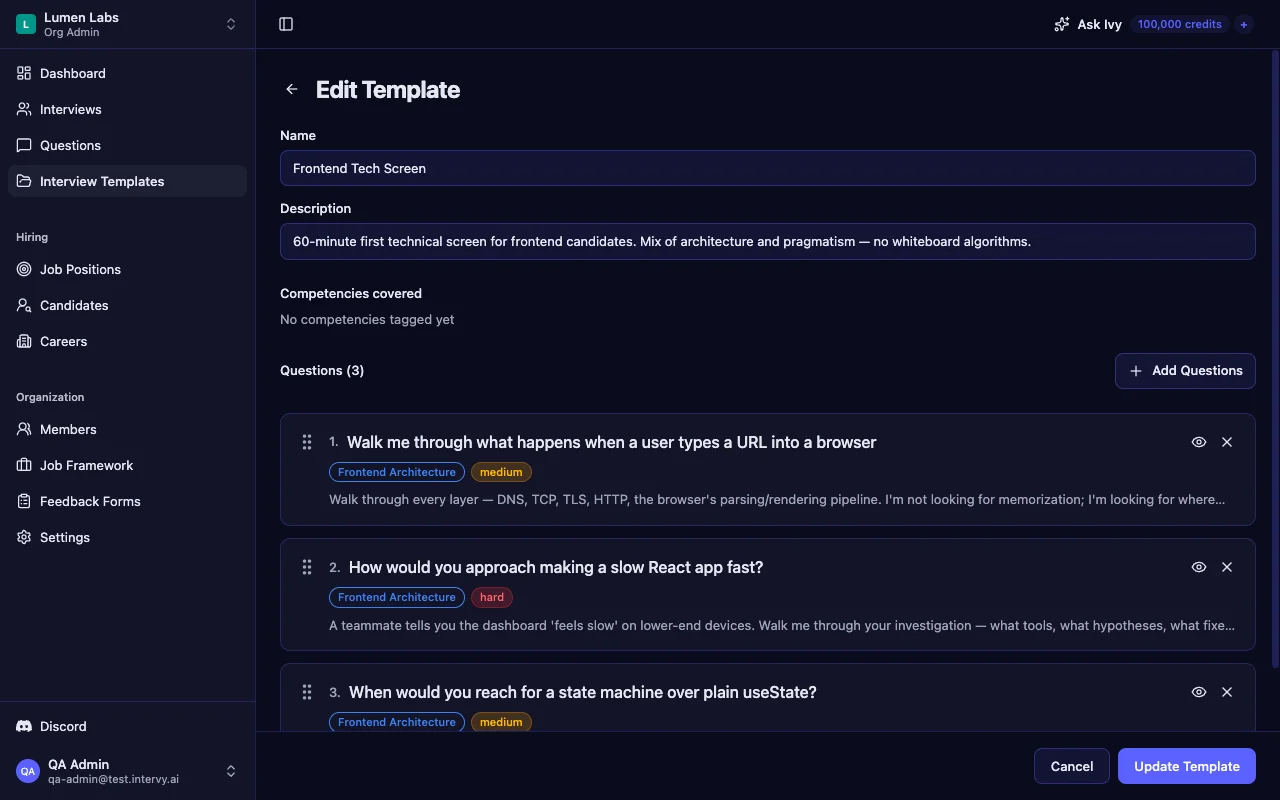
Intervy's interview template builder fixes this by default. Starting an interview copies every template question into the candidate's interview in one step, in the template's order — the question set is determined by the template, not by what the interviewer remembered to ask. For phase-based pipelines, you can lock a phase on the job position; a locked phase ignores any override and uses the template the hiring manager pinned.
- Same questions don't mean robotic. Follow-ups and clarifications still belong to the interviewer. Only the core set is locked.
- One template per role, not one per company. The Customer Success Lead template shouldn't be a re-skin of the Account Executive one.
- Lock per phase, not globally. A reference-check phase doesn't need the same lock that a competency-screen phase does.
For the deeper how-to, see How to Run Structured Technical Interviews That Actually Work.
Key takeaway: Different questions are the easiest place for bias to enter. A structured interview tool that enforces the same core questions per candidate doesn't make interviewing rigid — it makes it comparable.
3. Score in the Moment, on an Anchored Scale
Memory is a bias amplifier. By the time a debrief starts forty-eight hours later, every interviewer has built a tidy narrative about each candidate, and the rating becomes a justification of that narrative rather than a measurement of the answer.
Intervy stores a numeric rating per question on every answer, not a single end-of-interview overall score. Each rating and comment is saved one at a time, designed to be clicked the moment the candidate finishes. Completion doesn't require an aggregate score — the per-question ratings are the data.
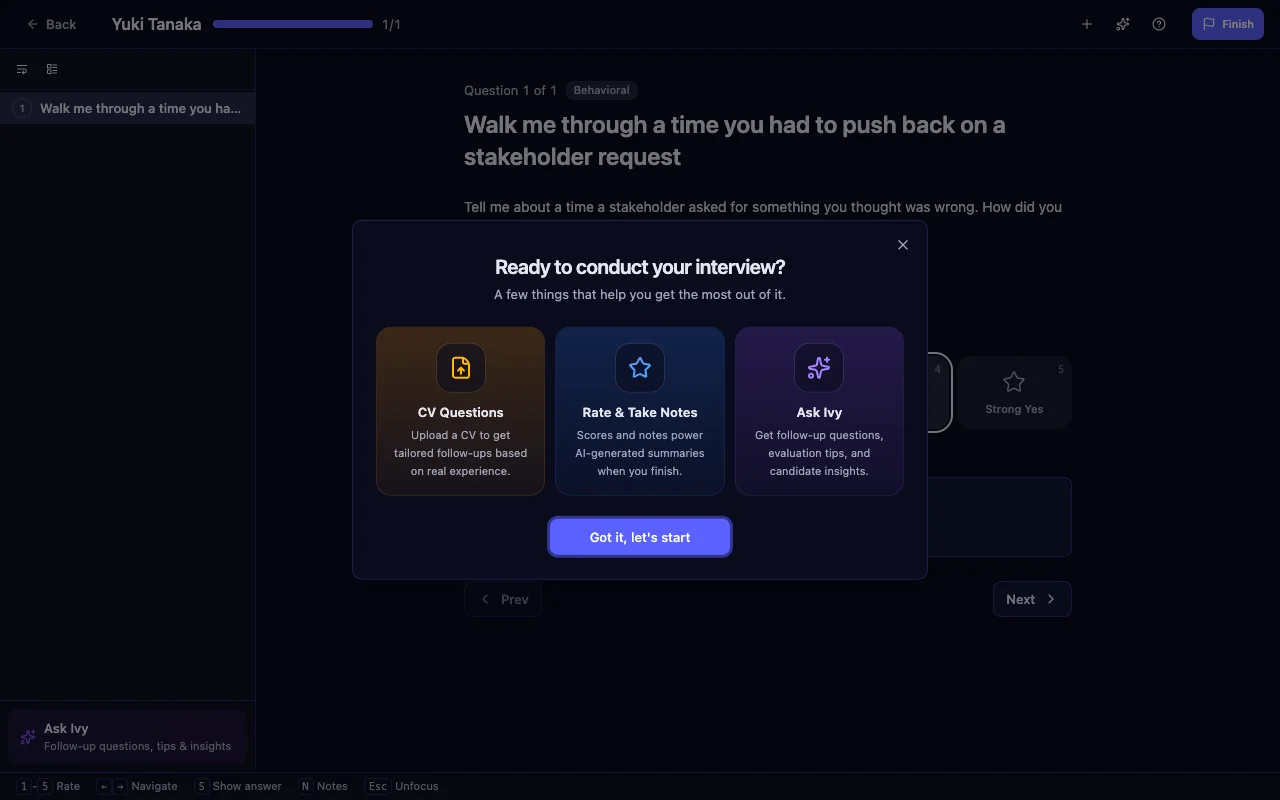
The other half of the fix is the scale itself. "3 out of 5" means nothing if every interviewer has their own definition of 3. Intervy's interview scoring tool ships with anchored labels at the org level — the default 5-level scale uses "Strong No, No, Maybe, Yes, Strong Yes," with presets for 3-level (No / Maybe / Yes) and 10-level (1 Unacceptable through 10 Outstanding). Each value has a name, not just a number. The scale is snapshotted onto every interview at start time, so changing the org scale next quarter doesn't rewrite last quarter's data.
- Click during the answer, not after. Two seconds beats two days of memory.
- Write the comment in the candidate's words. "Said 'we landed three F500 logos last year'" is auditable. "Strong commercial instincts" is a story.
- Lower the granularity if everyone clusters in the middle. A 10-level scale where everyone scores 5–7 is a 3-level scale wearing a costume.
For the conduct UX in depth, see How to Prepare for Technical Interviews with AI.
Tip: If an interviewer keeps wanting to "go back and adjust" scores after the fact, they're rebuilding a narrative. The score should change only if a later answer re-contextualized an earlier one — not because the debrief is uncomfortable.
4. Anonymize What You Can
You can't blind the live interview. A name is on the calendar invite, a face is on the video. But the resume-skimming step is where the most powerful bias signal lives — employer prestige, name origin, school logo — and that step you can scrub.
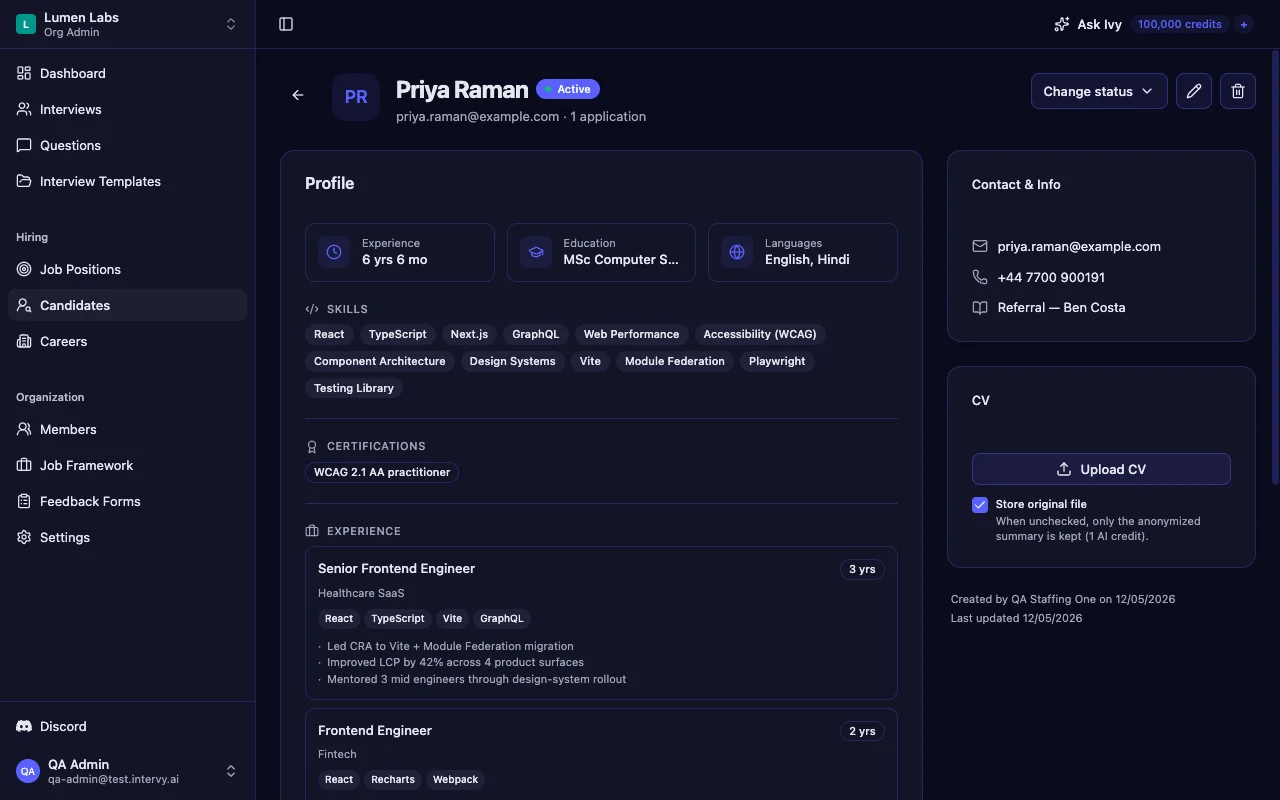
Intervy's candidate screening tool runs an explicit anonymization prompt on every uploaded CV: PII is stripped (names, emails, phone numbers, addresses, birth dates) and employer names are replaced with industry descriptors like "Fortune 500 tech company" or "mid-size consulting firm." The structured profile the model returns has no schema field for name, email, employer, or photo — only experience years, skills, education level, languages, certifications, role/period/domain/responsibilities, and project domains.
The candidate detail page surfaces that anonymized profile first; the raw CV download sits in a side column and is gated behind an HMAC-signed token with a 15-minute expiry, so the unredacted file isn't trivially shareable inside the org. The panel debates skills and roles, not logos. For the deeper pipeline, see Generate Interview Questions from CV.
Key takeaway: Don't claim blind interviews you can't deliver. Do anonymize the parts you can — the screening read — and put the raw CV behind a short-lived signed link so it's not the default artifact the panel sees.
5. Watch for the Cultural-Fit Fallacy
"Cultural fit" is the single most common backdoor for affinity bias. Two candidates with identical answers will get different ratings if one of them reminds the panel of themselves. The cure isn't to ban the phrase — it's to operationalize what you actually meant.
If "culture fit" means "this person collaborates well with strong opinions in the room," that's a competency. Write it on the rubric. Write the levels. Then write the question that probes it — and ask every candidate the same one.
- Engineering. "Walk me through a time you disagreed with a tech lead's design call. What did you do, and how did it land?"
- Sales. "A peer keeps pulling deals out of your territory. How do you raise it with your manager without burning the relationship?"
- PM. "A stakeholder wants a feature that conflicts with a quarterly OKR. What's your move?"
- Customer Success. "A top-tier account just churned. What's your week-one plan to rebuild trust with the rest of the book?"
- Marketing. "Your VP wants to kill a campaign you believe in based on early data. How do you respond?"
The phrase "cultural fit" never appears on the scorecard, because the things you actually meant by it are now four named competencies with anchored levels.
Tip: When a panelist says "I just didn't feel a cultural fit" in a debrief, ask: which competency on the rubric did they fail, and which answer was the evidence? If they can't point to a rubric row, the rating is intuition, not evaluation.
6. Calibrate the Panel Before Each Role Goes Live
Calibration is the practice everyone agrees with and nobody does. Two interviewers, same recorded or mock answer, rate independently, then compare and talk through the gaps. Thirty minutes. Saves three hires.
The reason it usually doesn't happen is friction: who picks the answer, where do the questions live, who tracks the gap? A structured interview tool removes most of that. The template is already there. The rubric is already there.
The approval workflow does the rest. Intervy ships templates and questions with an approval pipeline: publishing a new template is held for review if the author lacks approve permission, capturing a snapshot of the exact version being reviewed. Reviewers see exactly what they're approving — not "a template called Senior PM," but the actual question list. Every approval, rejection, withdrawal, or resubmission records who acted and when — so when the panel discovers one interviewer rates two points above the rest, you can go look at which questions and templates that interviewer published or approved.
- Calibrate on edge cases, not safe answers. A "Strong Yes" everyone agrees on is useless data. The "Maybe" that splits the panel is where you learn.
- Calibrate per role, not per interviewer. A team that calibrates well on engineering hires can still drift on PM hires.
- Calibrate by reviewing the gap, not the worst notes. Both interviewers were on the same call — both ratings are data.
Intervy doesn't schedule the calibration meeting for you. It does give you the artifacts — template, rubric, snapshot of the version under review, who approved it when — that turn a vague "we should calibrate more" into a concrete thirty-minute session.
Key takeaway: Calibration becomes practical the moment the panel has shared artifacts to point at. Without those, calibration is two people remembering different interviews.
7. Audit Who Did What After the Funnel Runs
You can't fix a hiring process you can't see. The seventh practice closes the loop: when the quarter ends and the offer rate looks off, can you reconstruct who did what?
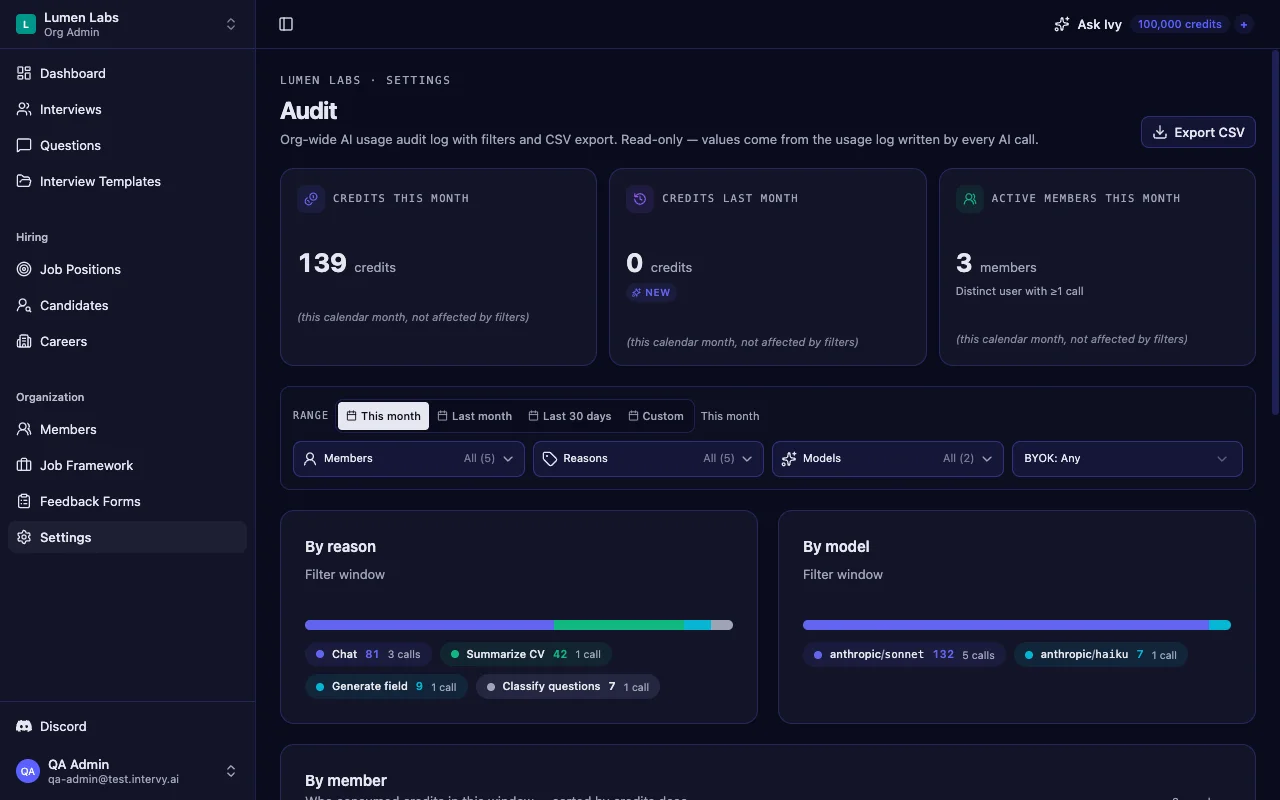
Intervy writes a ledger row for every paid AI call — CV summarization, question generation, interview summary — stamped with the member who made the call, the model used, tokens, and a reason. The org settings audit page renders summary cards plus a per-member breakdown, surfacing which member ran which AI action and when. Approval requests carry their own trail — who submitted, who reviewed, a snapshot of the version reviewed, and timestamps on every state change.
What this is not: an offer-rate parity report across demographic cohorts. Intervy doesn't store candidate race, gender, age, or other protected attributes on the candidate record, and there is no built-in dashboard comparing hiring outcomes across demographic groups. The audit page is AI-usage by member — useful for spotting process drift (one staffer running ten times more CV summaries than the rest of the team) and for answering "who edited the rubric" questions, not for legal compliance reporting.
Tip: Run the audit page monthly, not quarterly. The drift you catch in week three is one conversation; the drift you catch in week twelve is a re-train.
Common Pitfalls
Even teams that adopt the six previous practices fall into a predictable set of mistakes:
- Rating after the interview, not during it. Defeats the entire point of an anchored scale.
- Treating "cultural fit" as a competency in its own right. It's a placeholder for four real competencies you haven't named yet.
- Skipping calibration because the panel is busy. The hour you don't spend is paid back in mis-hires.
- Publishing templates and questions without review. Use the approval workflow — it exists for exactly this.
- Confusing anonymized profiles with blind interviews. The CV summary is anonymized. The live interview isn't.
Getting Started
Bias reduction isn't a campaign. It's seven cheap habits, annoying to maintain by hand and cheap once the tooling does the bookkeeping. Write the rubric. Lock the template. Score in the moment, against an anchored scale. Anonymize the CV read. Retire "cultural fit." Calibrate the panel. Audit the trail.
You don't need all seven at once. Start with the rubric and one locked template for one role. Run two hires through it. The signal-to-noise jump is immediate, and the next five practices become obvious from there. For a step-by-step onboarding path, see Getting Started with Intervy, and when you're ready to run a structured cycle end-to-end, head to app.intervy.ai.
The strongest predictor of a fair hire isn't the interviewer's intent. It's the structure they're operating inside.